러닝스푼즈 수업 정리
< 이전 글 >
https://silvercoding.tistory.com/66
[Bank Marketing데이터 분석] 1. python 배깅 , 랜덤포레스트 bagging, randomforest
러닝스푼즈 수업 정리 < 이전 글 > https://silvercoding.tistory.com/65 https://silvercoding.tistory.com/64 https://silvercoding.tistory.com/63?category=967543 https://silvercoding.tistory.com/62 [bost..
silvercoding.tistory.com
부스팅 Boosting
각 모델의 다양성 확보 (부스팅 절차)
- 이전 모델에서 오분류한 객체에 가중치를 높여 새로운 데이터(가중치가 부여된)로 모델 학습
- 각 데이터셋으로 모델 만듦
- 모델별로 학습하는 데이터셋의 다양성으로 인해 모델의 다양성 확보
최종 결과물 결합
- 각 모델로부터 나온 예측치를 가중평균
n_estimators 설정
(n_estimators : 몇 개의 의사결정나무를 만들 것인지)
- n_estimators 가 너무 높으면 노이즈에 민감한 오버피팅 우려
- n_estimators가 너무 낮으면 언더피팅 우려
- 적절한 n_estimators를 찾아내는 것이 관건
데이터 불러오기
import os
import pandas as pdos.chdir('../data') # 본인 파일이 존재하는 폴더 경로
data = pd.read_csv("bank-additional-full.csv", sep = ';')data.head()
data.info()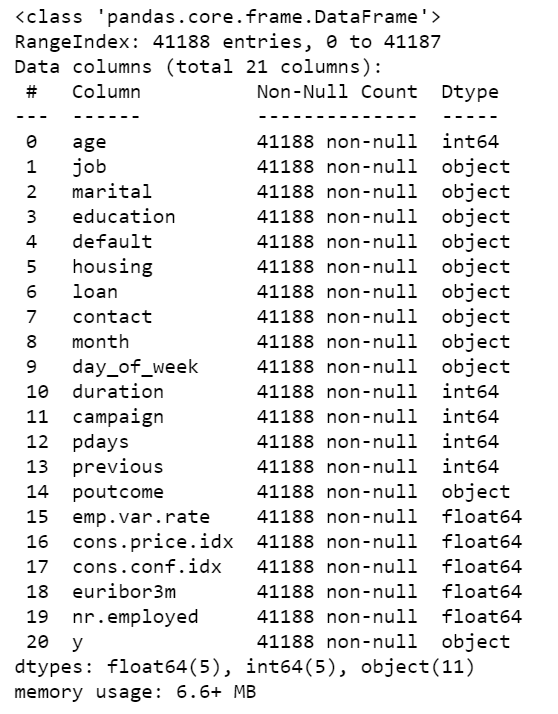
전처리 - 범주형 변수 원핫인코딩
data = pd.get_dummies(data,columns=['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome'])dtype이 object인 범주형 변수를 get_dummies를 사용하여 원핫인코딩 해준다.
train & test 데이터셋 분리
data['id']=range(len(data))데이터를 구분하기 위하여 각 row에 id를 부여한다.
train = data.sample(30000,replace=False,random_state=2020).reset_index().drop(['index'],axis=1)test = data.loc[ ~data['id'].isin(train['id']) ].reset_index().drop(['index'],axis=1)이전글과 동일하게 train, test 데이터셋을 분리해 준다.
인풋변수 저장
data.columns
input_var = ['age', 'duration', 'campaign', 'pdays', 'previous', 'emp.var.rate',
'cons.price.idx', 'cons.conf.idx', 'euribor3m', 'nr.employed',
'job_admin.', 'job_blue-collar', 'job_entrepreneur', 'job_housemaid',
'job_management', 'job_retired', 'job_self-employed', 'job_services',
'job_student', 'job_technician', 'job_unemployed', 'job_unknown',
'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'education_basic.4y', 'education_basic.6y',
'education_basic.9y', 'education_high.school', 'education_illiterate',
'education_professional.course', 'education_university.degree',
'education_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'contact_cellular', 'contact_telephone',
'month_apr', 'month_aug', 'month_dec', 'month_jul', 'month_jun',
'month_mar', 'month_may', 'month_nov', 'month_oct', 'month_sep',
'day_of_week_fri', 'day_of_week_mon', 'day_of_week_thu',
'day_of_week_tue', 'day_of_week_wed', 'poutcome_failure',
'poutcome_nonexistent', 'poutcome_success']data의 컬럼에서 y를 제외한 컬럼을 input_var에 저장해 준다.
XGBoost 모델학습
XGBoost
- 특징
- 해석이 어려움
- 대체적으로 랜덤포레스트에 비해 빠르고 성능이 좋음
- xgb = XGBClassifier( n_estimators = 300, learning_rate = 0.1 )
- n_estimators : 몇 개의 의사결정나무를 만들 것인지
- learning_rate : 얼마나 빠르게 학습할 것인지
-설치
!pip install xgboost우선 xgboost가 설치되어있지 않다면 설치해 준다.
from xgboost import XGBClassifierxgb = XGBClassifier( n_estimators = 300, learning_rate = 0.1 )
xgb.fit(train[input_var], train['y'])
객체 생성을 하고, train 데이터셋으로 학습까지 진행한다.
predictions = xgb.predict(test[input_var])test 데이터셋으로 예측을 수행한 후 predictions에 저장한다.
(pd.Series(predictions)==test['y']).mean()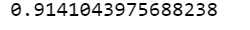
정확도가 약 91 % 가 나왔다. 현재 모델은 n_estimators를 300으로 지정하였다. 앞에서 학습하였듯이, 오버피팅과 언더피팅을 피하기 위해서는 부스팅에서 n_estimators를 적절하게 설정하는 것이 관건이라고 하였다. 따라서 최적의 n_estimators를 찾아보도록 한다.
최적 의사결정나무 수 ( n_estimators ) 찾기
for n in [100,200,300,400,500,600,700,800,900]:
xgb = XGBClassifier( n_estimators = n, learning_rate = 0.05, eval_metric='logloss' )
xgb.fit(train[input_var], train['y'])
predictions = xgb.predict(test[input_var])
print((pd.Series(predictions)==test['y']).mean())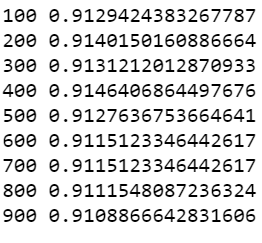
결과 : 최적의 n_estimators 는 400이다.
변수중요도
feature_imp = xgb.feature_importances_feature_importances_ 를 사용하여 변수중요도를 계산할 수 있다.
imp_df = pd.DataFrame({'var':input_var,
'imp':feature_imp})
imp_df.sort_values(['imp'],ascending=False)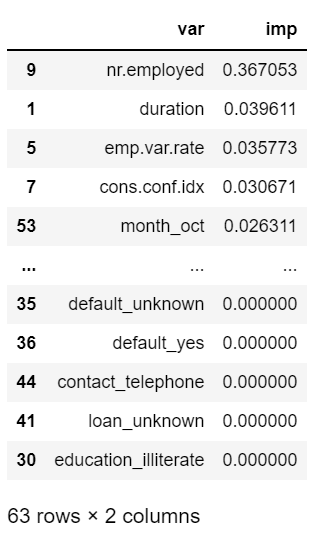
변수중요도를 내림차순으로 정렬해보니 nr.emplyed 컬럼이 가장 중요한 변수로 나온 것을 볼 수 있다.
'데이터 분석 이론 > 머신러닝' 카테고리의 다른 글
| [FIFA DATA] 2019/2020 시즌 Manchester United 에 어떤 선수를 영입해야 하는가?, EDA 과정 (0) | 2021.09.06 |
|---|---|
| [머신러닝] 변수중요도, shap value (0) | 2021.08.27 |
| [Bank Marketing데이터 분석] 1. python 배깅 , 랜덤포레스트 bagging, randomforest (0) | 2021.08.23 |
| [IRIS 데이터 분석] 2. Python Decision Tree ( 의사 결정 나무 ) (0) | 2021.08.20 |
| [IRIS 데이터 분석] 1. Python KNN 분류 (0) | 2021.08.20 |