코드 - 패캠 수업 코드 참고 (패캠 수업 정리)
<이전 글>
https://silvercoding.tistory.com/43
[python 기초] 11. 예외 종류와 처리 , try , except , else, raise
코드 - 패캠 수업 코드 참고 (패캠 수업 정리) <이전 글> https://silvercoding.tistory.com/42 https://silvercoding.tistory.com/41 https://silvercoding.tistory.com/40 https://silvercoding.tistory.com/39..
silvercoding.tistory.com
import csv우선 파이썬에서 csv를 사용하기 위해 import 해준다.
- 예제 1
with open('./resource/sample1.csv', 'r') as f:
reader = csv.reader(f)
# next(reader) # Header 스킵
# 확인
print(reader)
print(type(reader))
print(dir(reader))
print()
for c in reader:
print(c) # 하나의 row가 리스트 형식으로 나온다.<_csv.reader object at 0x0000013CD5F8E868>
<class '_csv.reader'>
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'dialect', 'line_num']
['번호', '이름', '가입일시', '나이']
['1', '김정수', '2017-01-19 11:30:00', '25']
['2', '박민구', '2017-02-07 10:22:00', '35']
['3', '정순미', '2017-01-22 09:10:00', '33']
['4', '김정현', '2017-02-22 14:09:00', '45']
['5', '홍미진', '2017-04-01 18:00:00', '17']
['6', '김순철', '2017-05-14 22:33:07', '22']
['7', '이동철', '2017-03-01 23:44:45', '27']
['8', '박지숙', '2017-01-11 06:04:18', '30']
['9', '김은미', '2017-02-08 07:44:33', '51']
['10', '장혁철', '2017-12-01 13:01:11', '16']
여기서 header를 제거하고 싶으면 위의 주석으로 작성되어 있는 next(reader)를 사용하면 된다.
- 예제 2 : delimiter

vs로 여니까 글씨가 깨지지만 콤마가 아닌 |로 구분되어 있는 csv파일이기 때문에 구분자를 , 에서 | 로 바꾸어주어야 한다.
with open('./resource/sample2.csv', 'r') as f:
reader = csv.reader(f, delimiter='|')
# next(reader) # Header 스킵
# 확인
print(reader)
print(type(reader))
print(dir(reader))
print()
for c in reader:
print(c)<_csv.reader object at 0x0000013CD5EA5798>
<class '_csv.reader'>
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'dialect', 'line_num']
['번호', '이름', '가입일시', '나이']
['1', '김정수', '2017-01-19 11:30:00', '25']
['2', '박민구', '2017-02-07 10:22:00', '35']
['3', '정순미', '2017-01-22 09:10:00', '33']
['4', '김정현', '2017-02-22 14:09:00', '45']
['5', '홍미진', '2017-04-01 18:00:00', '17']
['6', '김순철', '2017-05-14 22:33:07', '22']
['7', '이동철', '2017-03-01 23:44:45', '27']
['8', '박지숙', '2017-01-11 06:04:18', '30']
['9', '김은미', '2017-02-08 07:44:33', '51']
['10', '장혁철', '2017-12-01 13:01:11', '16']
delimiter = '|' 를 사용했더니 잘 나누어진 것을 볼 수 있다.
- 예제 3 : dictionary로 읽어오기 => DictReader
with open('./resource/sample1.csv', 'r') as f:
reader = csv.DictReader(f)
for c in reader:
for k, v in c.items():
print(k, v)
print("------------------")번호 1
이름 김정수
가입일시 2017-01-19 11:30:00
나이 25
------------------
번호 2
이름 박민구
가입일시 2017-02-07 10:22:00
나이 35
------------------
번호 3
이름 정순미
가입일시 2017-01-22 09:10:00
나이 33
------------------
번호 4
이름 김정현
가입일시 2017-02-22 14:09:00
나이 45
------------------
번호 5
이름 홍미진
가입일시 2017-04-01 18:00:00
나이 17
------------------
번호 6
이름 김순철
가입일시 2017-05-14 22:33:07
나이 22
------------------
번호 7
이름 이동철
가입일시 2017-03-01 23:44:45
나이 27
------------------
번호 8
이름 박지숙
가입일시 2017-01-11 06:04:18
나이 30
------------------
번호 9
이름 김은미
가입일시 2017-02-08 07:44:33
나이 51
------------------
DictReader를 통하여 딕셔너리로 읽어오면 ,
OrderedDict([('번호', '1'), ('이름', '김정수'), ('가입일시', '2017-01-19 11:30:00'), ('나이', '25')])
이런 식으로 하나의 줄마다 OrderedDict가 생성된다. 따라서 위와 같은 코드로 key와 value를 뽑아내줄 수 있는 것이다.
- 예제 4 : writerow
w = [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12], [13, 14, 15], [16, 17, 18]]
with open('./resource/sample3.csv', 'w', newline='') as f:
wt = csv.writer(f)
for v in w:
wt.writerow(v) # 하나하나 검수해서 쓸 떄 (if같은 조건이 들어갈 때 )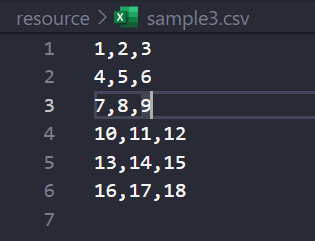
writerow로 한줄씩 검수해가며 작성을 해줄 수 있다.
- 예제 5 : writerows
with open('./resource/sample4.csv', 'w', newline='') as f:
wt = csv.writer(f)
wt.writerows(w) # 아에 한번에 쓰는 것
한번에 쓰는 writerows함수도 존재한다. for문을 사용할 필요가 없다.
- 예제 6 : excel
* XSL, XLSX
: openpyxl, xlswriter, xlrd, xlwt, xlutils
: pandas 를 주로 사용 (openpyxl, xlrd)
* 설치 (pandas, openpyxl, xlrd)
- pip install xlrd
- pip install openpyxl
- pip install pandas
* 불러오기
import pandas as pd
xlsx = pd.read_excel('./resource/sample.xlsx')pandas를 import하고, read_excel을 이용하여 엑셀 파일을 불러와 준다.
* 상위 데이터 확인
print(xlsx.head()) Sap Co. 대리점 영업사원 전월 금월 TEAM 총 판매수량
0 KI1316 경기수원대리점 이기정 1720000 2952000 1 123
1 KI1451 충청홍성대리점 정미진 4080000 2706000 2 220
2 KI1534 경기화성대리점 경인선 600000 2214000 1 320
3 KI1636 강원속초대리점 이동권 3720000 2870000 3 110
4 KI1735 경기안양대리점 강준석 4800000 2296000 1 134
기본적으로 가장 위의 5개 데이터가 나온다.
* 하위 데이터 확인
print(xlsx.tail()) Sap Co. 대리점 영업사원 전월 금월 TEAM 총 판매수량
15 KI2870 경기구리시대리점 박진형 6000000 3400000 2 143
16 KI2910 강원춘천대리점 김은향 4800000 4896000 1 176
17 KI3030 강원영동대리점 전수창 4560000 3128000 2 98
18 KI3131 경기하남대리점 김민정 2750000 7268000 3 293
19 KI3252 강원포천대리점 서가은 2420000 4740000 4 240
하위 5개의 데이터를 보여준다.
* 데이터의 구조
print(xlsx.shape) # 행, 열(20, 7)
shape를 이용하여 행과 열의 크기가 얼마나 되는지 확인해 볼 수 있다.
* 엑셀 or CSV 다시 쓰기
xlsx.to_excel('./resource/result.xlsx', index=False)
xlsx.to_csv('./resource/result.csv', index=False)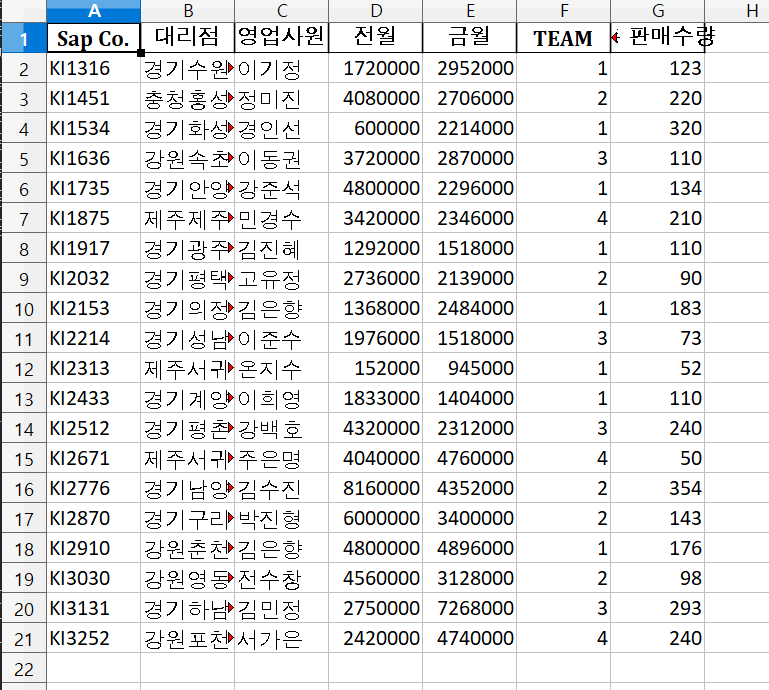
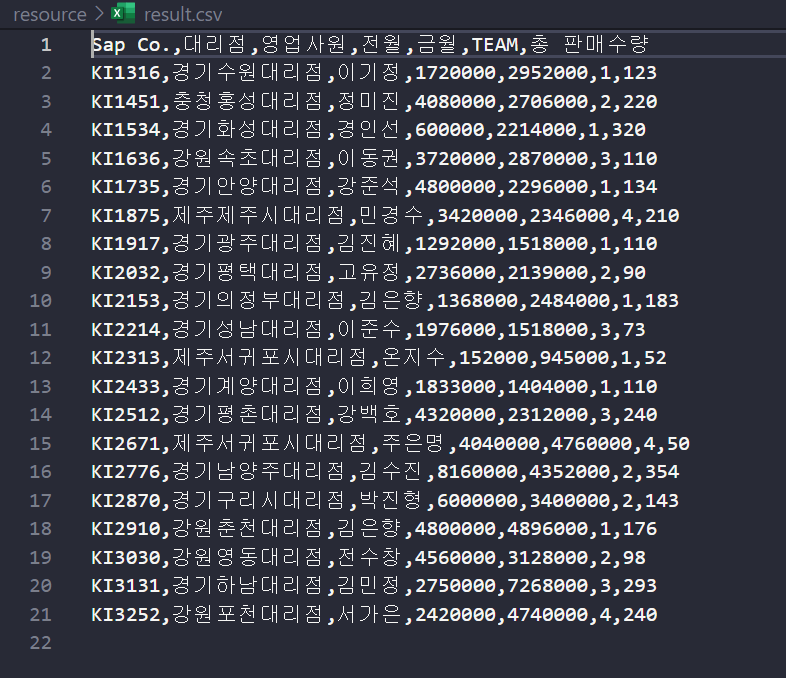
이렇게 to_excel과 to_csv를 이용하여 파일을 생성할 수도 있다.
'프로그래밍 언어 > Python' 카테고리의 다른 글
| [python 기초] 14. SQLITE 데이터베이스 연동 (2) - 테이블 조회 (0) | 2021.08.03 |
|---|---|
| [python 기초] 13. SQLITE 데이터베이스 연동 (1) - 테이블 생성 및 삽입 삭제 (0) | 2021.08.03 |
| [python 기초] 11. 예외 종류와 처리 , try , except , else, raise (0) | 2021.08.02 |
| [python 기초] 10. 파일 읽기 , 쓰기 (open) (0) | 2021.08.02 |
| [python 기초] 9. 모듈과 패키지 (0) | 2021.08.02 |