러닝스푼즈 수업 정리
< 이전 글 >
https://silvercoding.tistory.com/50
[python pandas] 3. pandas 기초 사용 (3) - 집계, 결측값, 정렬
러닝스푼즈 수업 정리 < 이전 글 > https://silvercoding.tistory.com/49 https://silvercoding.tistory.com/48 [python pandas] pandas 기초 사용 (1) 러닝스푼 수업 정리 * 판다스 기본 함수 데이터 파일 읽기 :..
silvercoding.tistory.com
데이터 불러오기 & 살펴보기
import pandas as pdfile = './data/babyNamesUS.csv'
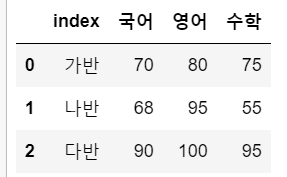
raw = pd.read_csv(file)raw.head()
raw.info()
남녀 구분없이 '많이' 사용되는 공통 이름 ?
idea : 남녀 이름 개수의 비율 차이가 작을수록 성별 구분이 없는 이름일 것이다 !
# 성별에 따른 이름 개수 집계
name_df = raw.pivot_table(index = 'Name', columns = 'Sex', values = 'Number', aggfunc='sum')
# 결측값 채우기 (0)
name_df = name_df.fillna(0)
# float -> int
name_df = name_df.astype(int)
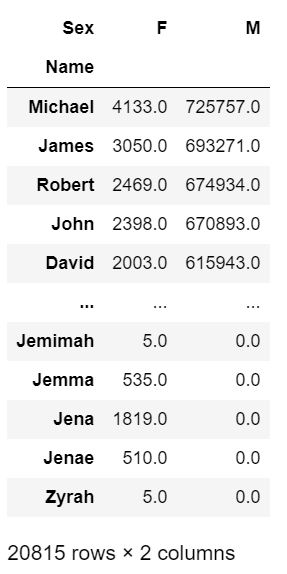
name_df.head()
여기까지 저번 포스팅에서 했던 내용이다.
name_df['Sum'] = name_df['M'] + name_df['F']
name_df.head()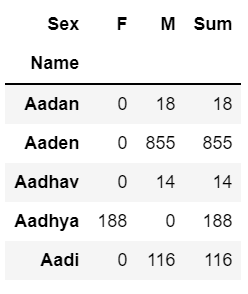
남녀 이름 개수를 모두 더해서 sum 이라는 컬럼을 생성한다.
# 남, 녀 비율 계산
name_df['F_ratio'] = name_df['F'] / name_df['Sum']
name_df['M_ratio'] = name_df['M'] / name_df['Sum']
# 남, 녀 비율 간 차이
name_df['M_F_Gap'] = abs(name_df['F_ratio'] - name_df['M_ratio'])
name_df.head()
-1 ~ 1 의 범위를 abs() (절댓값) 를 사용하여 0 ~ 1 범위로 바꾸어 준다.
# 이름 총 개수를 기준으로 내림차순 정렬
name_df = name_df.sort_values(by = 'Sum', ascending=False)
name_df.head(20)
많이 사용된 이름을 뽑는 것이기 때문에 우선 총 합계 컬럼을 기준으로 정렬해준다.
cond = name_df['M_F_Gap'] < 0.1
name_df[cond].head(10)
이 때 비율차이가 적은 것을 0.1 미만으로 기준 잡고, M_F_Gap 컬럼이 0.1 보다 작은 행들을 출력시킨다.
# 성별 구분없이 많이 사용되는 이름 Top 10
name_df[cond].head(10).index
가장 대표적인 미국의 이름 ? ( 최근 트렌드 )
idea : 세대를 기준으로 최근 세대(2020, 1990) 이름 개수의 비율이 큰 이름이 최근 트렌드에 맞는 대표적인 미국 이름일 것이다 !
raw.head()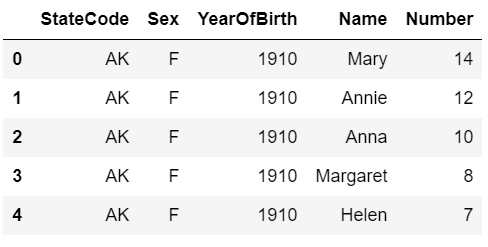
# unique() 를 통해, 기간에 들어가는 값들을 살펴봅니다.
raw['YearOfBirth'].unique()array([1910, 1911, 1912, 1913, 1914, 1915, 1916, 1917, 1918, 1919, 1920, 1921, 1922, 1923, 1924, 1925, 1926, 1927, 1928, 1929, 1930, 1931, 1932, 1933, 1934, 1935, 1936, 1937, 1938, 1939, 1940, 1941, 1942, 1943, 1944, 1945, 1946, 1947, 1948, 1949, 1950, 1951, 1952, 1953, 1954, 1955, 1956, 1957, 1958, 1959, 1960, 1961, 1962, 1963, 1964, 1965, 1966, 1967, 1968, 1969, 1970, 1971, 1972, 1973, 1974, 1975, 1976, 1977, 1978, 1979, 1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989, 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015], dtype=int64)
* 세대 나누기
한 세대 나누는 기준 30년 : 2020년 기준 30년씩 구분
- 1930년대 이전
- 1960년대 이전
- 1990년대 이전
- 2020년 이전
year_class_list = [ ]
for year in raw['YearOfBirth']:
if year <= 1930:
year_class = '1930년이전'
elif year<= 1960:
year_class = '1960년이전'
elif year <= 1990:
year_class = '1990년이전'
else:
year_class = '2020년이전'
year_class_list.append(year_class)위와같이 반복문과 if문을 사용하여 출생년도를 4개의 세대 그룹으로 나누어 준다.
raw['year_class'] = year_class_list
raw.head()
세대 그룹을 저장한 리스트를 이용하여 year_class 컬럼을 생성한다.
name_period = raw.pivot_table(index = ['Name', 'Sex'], columns = 'year_class', values = 'Number', aggfunc='sum')
name_period = name_period.fillna(0)
name_period = name_period.astype(int)
name_period.head()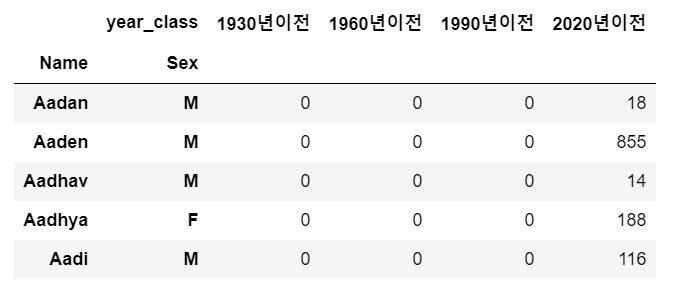
이름과 성별을 인덱스로 설정하고, year_class에 따른 number의 합계를 출력한다.
name_period['sum'] = name_period.sum(axis = 1)
name_period.head()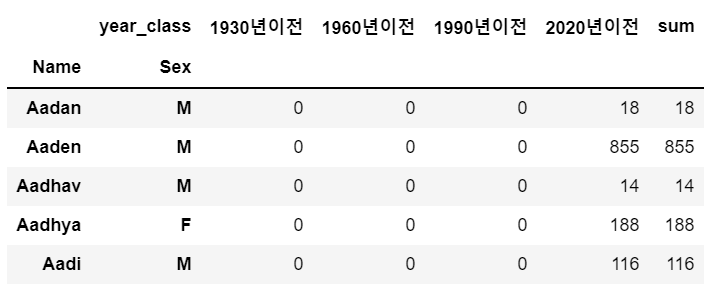
이름 총 개수를 구하기 위해 sum(axis=1) 을 사용한다. axis=1이면 가로방향으로 계산을 하게 된다.
# 세대 별 비율 계산
for col in name_period.columns:
col_new = col+"비율"
name_period[col_new] = name_period[col] / name_period['sum']
name_period.head()
세대 별 비율을 계산하여 각 컬럼을 만들어 준다.
# 이름 사용수 합계, 2020년 이전 비율, 1990년이전 비율 기준 내림차순 정렬
name_period = name_period.sort_values(by = ['sum', '2020년이전비율','1990년이전비율'], ascending=False)
name_period
1순위 이름 개수 총 합 , 2순위 2020년 이전 비율 , 3순위 1990년 이전 비율 로 정렬을 하여 최신 트렌드에 맞는 미국 대표이름을 알아본다.
# 인덱스가 여러 레벨로 되어있을 경우, 인덱스를 활용해 컨트롤 하는 것은 복잡
# reset_index()를 활용하여 인덱스로 설정된 이름과 성별을 컬럼으로 변경
name_period = name_period.reset_index()
name_period.head()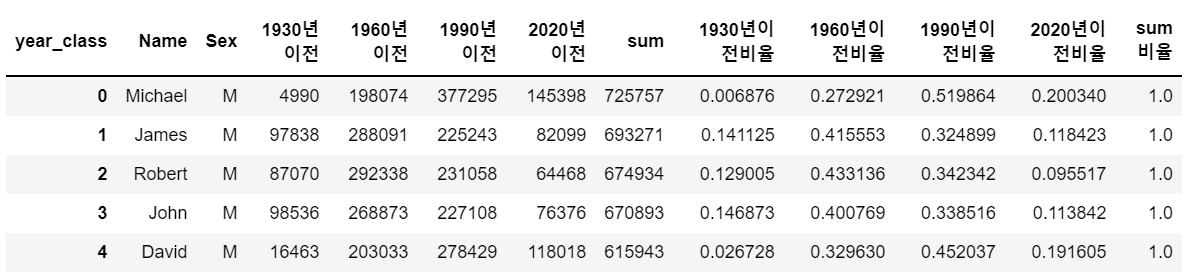
인덱스를 활용하여 컨트롤이 어려우므로 필요한 집계, 연산이 끝난 뒤에는 reset_index를 사용하여 column으로 변경해 준다.
# 남자 이름만 선택
cond = name_period['Sex'] =='M'
name_period[cond].head(10)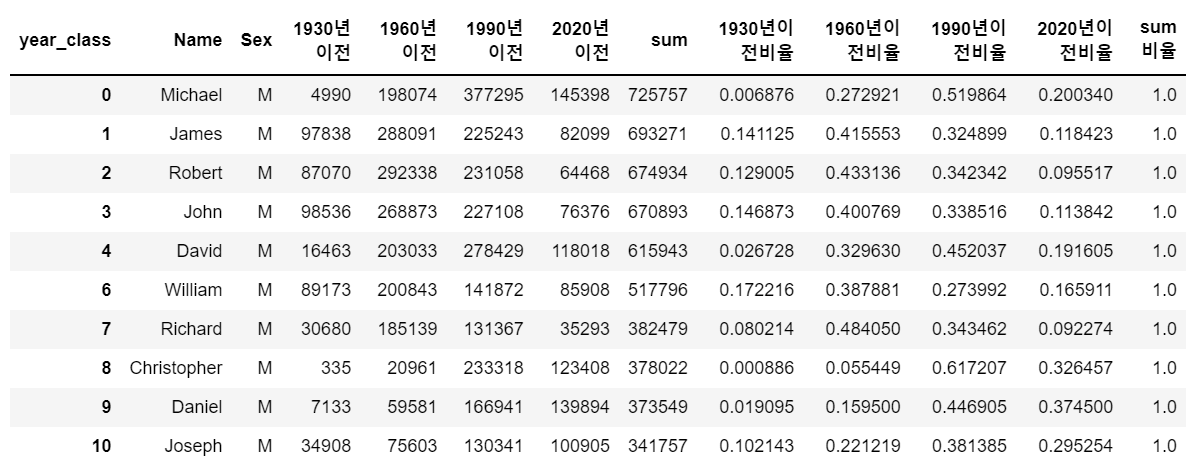
성별이 남성인 이름들 중에서 상위 10개를 뽑아보면 위와 같다.
# 이번에는 여자이름
cond = name_period['Sex'] =='F'
name_period[cond].head(10)
이번엔 성별이 여성인 이름의 상위 10개를 뽑은 것이다.
그런데 아직은 이상하다. 특히 성별이 여자인 이름의 표에서 첫번째 row는 1960년 이전 세대에서 약 50%의 비율을 차지하고 있다. 따라서 다음과 같은 조건을 건다.
cond_age = name_period['2020년이전비율'] > 0.3
cond_sex = name_period['Sex'] == 'M'
cond = cond_age & cond_sex
name_period[cond].head(5)
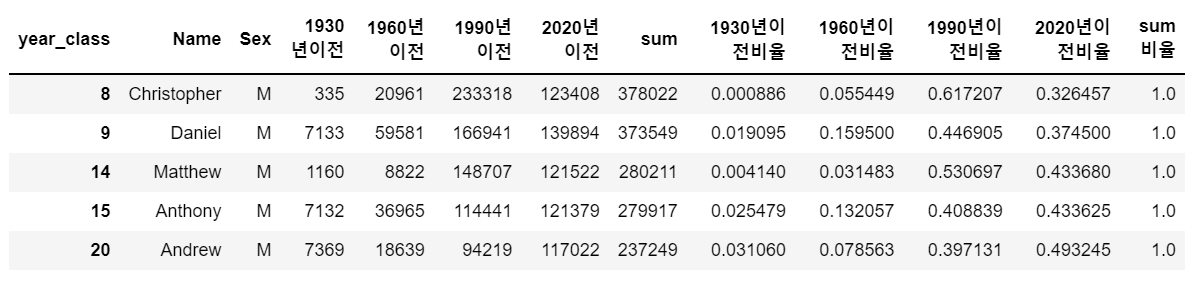
2020년 이전비율이 0.3 이상이면서 성별이 남성인 조건인 row를 선택한다.
결과 : < 남성 Top 5 이름 Christopher, Daniel, Matthew, Anthony, Andrew >
cond_age = name_period['2020년이전비율'] > 0.3
cond_sex = name_period['Sex'] == 'F'
cond = cond_age & cond_sex
name_period[cond].head(5)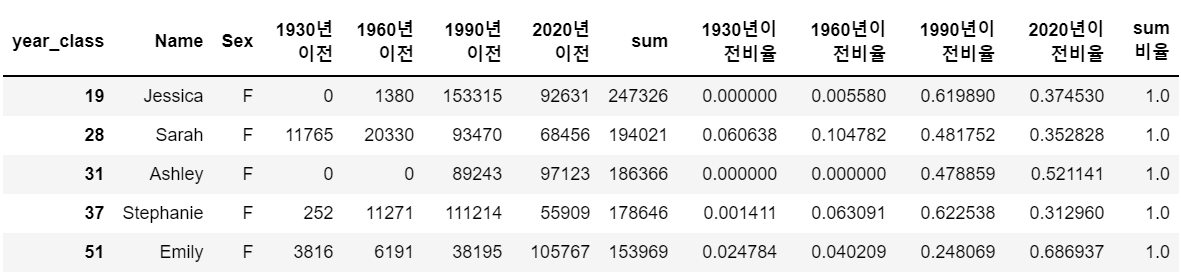
여성의 경우도 동일한 조건으로 진행한다.
결과 : < 여성 Top 5 이름 Jessica, Sarah, Ashley, Stephanie, Emily >
'데이터 분석 이론 > pandas' 카테고리의 다른 글
| [python pandas] 3. pandas 기초 사용 (3) - 집계, 결측값, 정렬 (0) | 2021.08.05 |
|---|---|
| [python pandas] 2. pandas 기초 사용 (2) - 추가, 병합, 저장 (0) | 2021.08.04 |
| [python pandas] 1. pandas 기초 사용 (1) (0) | 2021.08.04 |