러닝스푼즈 수업 정리
<이전 글>
https://silvercoding.tistory.com/71
[rossmann data]상점 매출 예측/ kaggle 축소데이터
러닝스푼즈 수업 정리 <이전 글> https://silvercoding.tistory.com/70 https://silvercoding.tistory.com/69 https://silvercoding.tistory.com/67 https://silvercoding.tistory.com/66 https://silvercoding.ti..
silvercoding.tistory.com
1. 데이터 소개 & 데이터 불러오기
[ Home Credit Data ]
원본 데이터: 캐글
학습용 데이터: 러닝스푼즈 제공
- 고객의 대출 상환능력 예측: 고객의 인적 정보, 거래 데이터를 바탕으로 해당 고객에게 돈을 빌려주었을 때 이를 상환할지 여부를 예측
train.csv - 학습 데이터
test.csv - 예측해야 할 test 데이터
loan_before.csv - 각 사람이 이전에 진행했던 대출에 대한 상세 정보
import pandas as pd
import osos.chdir('../data')lb = pd.read_csv("loan_before.csv")
train = pd.read_csv("train.csv")
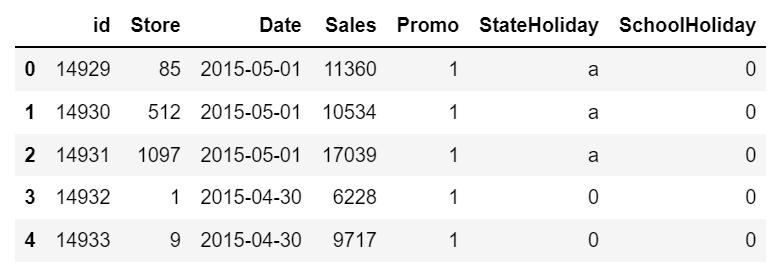
test = pd.read_csv("test.csv")train.head()
lb.head()
- loan before 컬럼 정보
| 유니크한 아이디 |
SK_ID_CURR |
| 해당 대출이 home credit으로부터 받은 대출보다 며칠 이전에 일어났는지 | DAYS_CREDIT |
| 대출 연장을 몇 번 했는지 | CNT_CREDIT_PROLONG |
| 대출금액 | AMT_CREDIT_SUM |
| 대출 유형 | CREDIT_TYPE |
- train, test 컬럼 정보
| 유니크한 아이디 |
SK_ID_CURR |
| 타겟값(0: 정상 상환, 1: 연체 혹은 문제가 생긴 경우) | TARGET |
| 성별(0: 여성, 1: 남성) | CODE_GENDER |
| 차 보유 여부(0: 없음, 1: 있음) | FLAG_OWN_CAR |
| 주택 혹은 아파트 보유 여부(0: 없음, 1: 있음) | FLAG_OWN_REALTY |
| 자녀 수 | CNT_CHILDREN |
| 수입 | AMT_INCOME_TOTAL |
| 대출금액 | AMT_CREDIT |
| 1달마다 갚아야 하는 금액 | AMT_ANNUITY |
| 대출신청을 할 때 누가 동행했는지 | NAME_TYPE_SUITE |
| 직업 종류 | NAME_INCOME_TYPE |
| 학위 | NAME_EDUCATION_TYPE |
| 주거 상황 | NAME_HOUSING_TYPE |
| 지역의 인구 | REGION_POPULATION_RELATIVE |
| 나이 | DAYS_BIRTH |
| 언제 취업했는지(365243는 결측치) | DAYS_EMPLOYED |
| 고객이 대출을 신청한 ID 문서를 변경한 날짜 | DAYS_ID_PUBLISH |
| 보유한 차의 나이 | OWN_CAR_AGE |
| 가족 수 | CNT_FAM_MEMBERS |
| 언제 대출신청을 했는지 시간 | HOUR_APPR_PROCESS_START |
| 일하는 조직의 종류 | ORGANIZATION_TYPE |
| 외부 데이터1로부터 신용점수 | EXT_SOURCE_1 |
| 외부 데이터2로부터 신용점수 | EXT_SOURCE_2 |
| 외부 데이터3로부터 신용점수 | EXT_SOURCE_3 |
| 마지막 핸드폰을 바꾼 시기 | DAYS_LAST_PHONE_CHANGE |
| 신청 전 1년간 신용평가기관에 해당 사람에 대한 신용정보를 조회한 개수 | AMT_REQ_CREDIT_BUREAU_YEAR |
1. 문제 정의
질문 1 - 어떤 요소가 대출금 상환 여부에 큰 영향을 주는가?
질문 2 - 그 요소들이 상환여부에 어떤 영향을 주는가?
2. 방법론
- 분석 과정
질문에 대한 해답을 얻기 위해 해석가능한 머신러닝 (xAI) 활용
(1) Feature Engineering
- AMT_CREDIT_TO_ANNUITY_RATIO 변수 생성: 해당 사람이 몇개월에 걸쳐 돈을 갚아야 하는지
train['AMT_CREDIT_TO_ANNUITY_RATIO'] = train['AMT_CREDIT']/train['AMT_ANNUITY']
test['AMT_CREDIT_TO_ANNUITY_RATIO'] = test['AMT_CREDIT']/test['AMT_ANNUITY']- lb데이터: groupby 후 평균
- AMT_CREDIT_SUM (이전 대출의 금액)
- DAYS_CREDIT (train, test의 대출로부터 며칠 전에 이전 대출을 진행했는지)
- CNT_CREDIT_PROLONG (대출연장을 몇 번 했는지)
train = pd.merge( train,lb.groupby(['SK_ID_CURR'])['AMT_CREDIT_SUM'].mean().reset_index(),on='SK_ID_CURR',how='left' )
test = pd.merge( test,lb.groupby(['SK_ID_CURR'])['AMT_CREDIT_SUM'].mean().reset_index(),on='SK_ID_CURR',how='left' )
train = pd.merge( train,lb.groupby(['SK_ID_CURR'])['DAYS_CREDIT'].mean().reset_index(),on='SK_ID_CURR',how='left' )
test = pd.merge( test,lb.groupby(['SK_ID_CURR'])['DAYS_CREDIT'].mean().reset_index(),on='SK_ID_CURR',how='left' )
train = pd.merge( train,lb.groupby(['SK_ID_CURR'])['CNT_CREDIT_PROLONG'].mean().reset_index(),on='SK_ID_CURR',how='left' )
test = pd.merge( test,lb.groupby(['SK_ID_CURR'])['CNT_CREDIT_PROLONG'].mean().reset_index(),on='SK_ID_CURR',how='left' )- lb 데이터: groupby 후 갯수
- count 컬럼 생성: 해당 사람이 이전에 대출을 몇 번 진행했는지
train = pd.merge(train , lb.groupby(['SK_ID_CURR']).size().reset_index().rename(columns={0:'count'}),on='SK_ID_CURR', how='left')
test = pd.merge(test , lb.groupby(['SK_ID_CURR']).size().reset_index().rename(columns={0:'count'}),on='SK_ID_CURR', how='left')
- 변수 제거
해당 프로젝트의 목적은 모델 해석이기 때문에, 이에 방해를 주는 변수는 모두 제거
제거 변수목록
- CODE_GENDER : 범주형 변수
- FLAG_OWN_CAR : 범주형 변수
- NAME_TYPE_SUITE : 범주형 변수
- NAME_INCOME_TYPE : 범주형 변수
- NAME_EDUCATION_TYPE : 범주형 변수
- NAME_HOUSING_TYPE : 범주형 변수
- ORGANIZATION_TYPE : 범주형 변수
- EXT_SOURCE_1 : 변수의 의미를 정확히 모름
- EXT_SOURCE_2 : 변수의 의미를 정확히 모름
- EXT_SOURCE_3 : 변수의 의미를 정확히 모름
del_list = ['CODE_GENDER','FLAG_OWN_CAR','NAME_TYPE_SUITE','NAME_INCOME_TYPE','NAME_EDUCATION_TYPE','NAME_HOUSING_TYPE','ORGANIZATION_TYPE',
'EXT_SOURCE_1','EXT_SOURCE_2','EXT_SOURCE_3']train = train.drop(del_list,axis=1)
test = test.drop(del_list,axis=1)train.columns
(2) 모델링
- 상관관계가 높은 input변수는 삭제한다.
: Input 변수가 높은 상관성을 띌 때 shap value는 제대로 된 설명력을 발휘하지 못함.
input_var = ['FLAG_OWN_REALTY', 'CNT_CHILDREN',
'AMT_INCOME_TOTAL', 'AMT_CREDIT', 'AMT_ANNUITY',
'REGION_POPULATION_RELATIVE', 'DAYS_BIRTH', 'DAYS_EMPLOYED',
'DAYS_ID_PUBLISH', 'OWN_CAR_AGE', 'CNT_FAM_MEMBERS',
'HOUR_APPR_PROCESS_START', 'DAYS_LAST_PHONE_CHANGE',
'AMT_REQ_CREDIT_BUREAU_YEAR', 'AMT_CREDIT_TO_ANNUITY_RATIO',
'AMT_CREDIT_SUM', 'DAYS_CREDIT', 'CNT_CREDIT_PROLONG', 'count']타겟변수인 TARGET 을 제외한 변수들을 input_var 에 저장해준다.
corr = train[input_var].corr()
corr.style.background_gradient(cmap='coolwarm')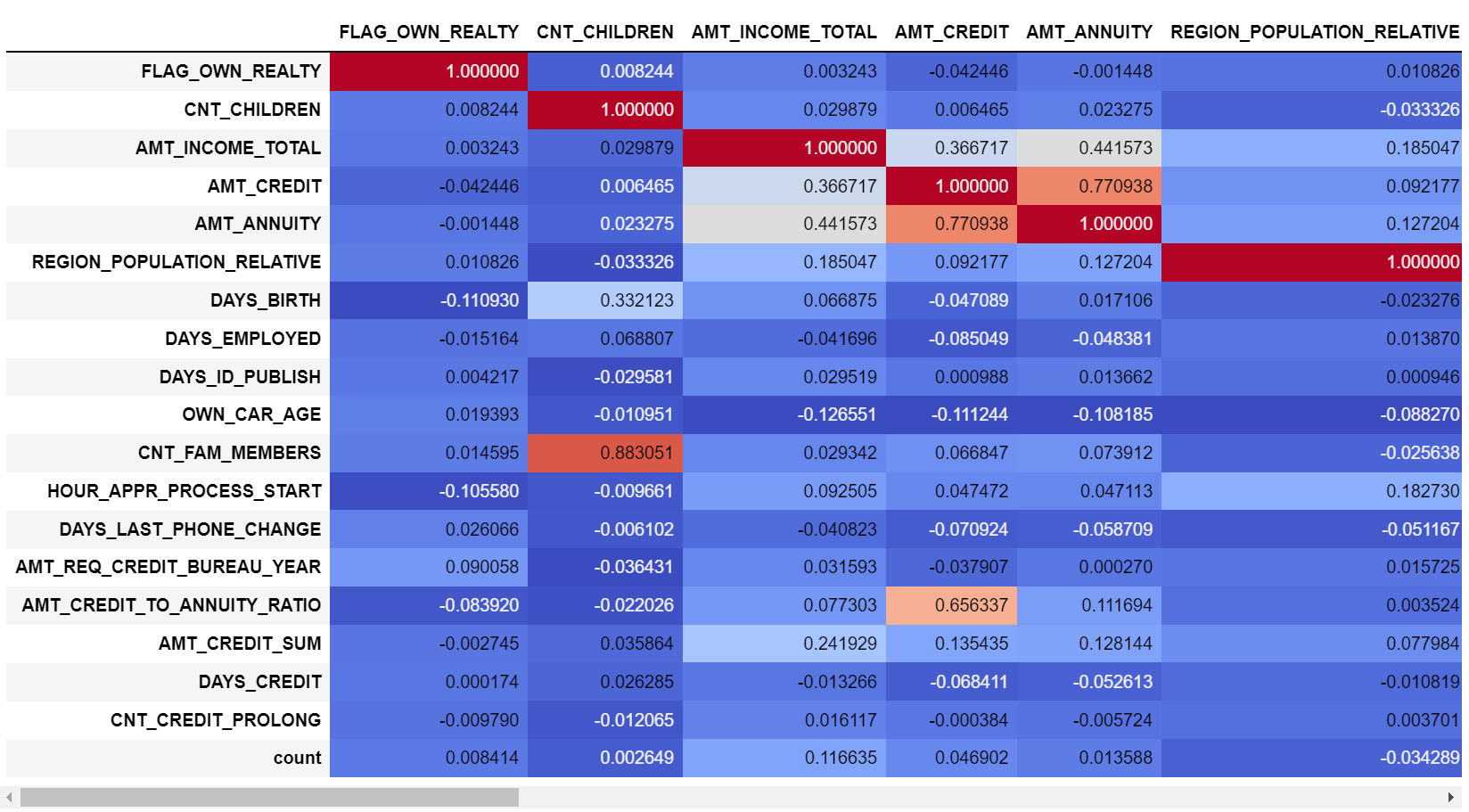
위와 같은 형태의 시각화 그래프가 그려지고, 높은 상관성을 띄는 변수들을 나열하면 다음과 같다.
[ 높은 상관성을 띄는 변수 목록 ]
- CNT_FAM_MEMBERS & CNT_CHILDREN 0.883051
- AMT_CREDIT_TO_ANNUITY_RATIO & AMT_CREDIT 0.656337
- AMT_ANNUITY & AMT_CREDIT 0.770938
cf) 피어슨 상관계수의 해석
r이 -1.0과 -0.7 사이이면, 강한 음적 선형관계,
r이 -0.7과 -0.3 사이이면, 뚜렷한 음적 선형관계,
r이 -0.3과 -0.1 사이이면, 약한 음적 선형관계,
r이 -0.1과 +0.1 사이이면, 거의 무시될 수 있는 선형관계,
r이 +0.1과 +0.3 사이이면, 약한 양적 선형관계,
r이 +0.3과 +0.7 사이이면, 뚜렷한 양적 선형관계,
r이 +0.7과 +1.0 사이이면, 강한 양적 선형관계
타겟 변수와의 상관성이 더 낮은 변수를 제거한다.
print(train['CNT_FAM_MEMBERS'].corr(train['TARGET']))
print(train['CNT_CHILDREN'].corr(train['TARGET']))0.018876651698723705
0.025357359317615676
del train['CNT_FAM_MEMBERS']
del test['CNT_FAM_MEMBERS']CNT_FAM_MEMBERS가 TARGET과의 상관계수가 더 낮으므로 제거해 준다.
print(train['AMT_CREDIT_TO_ANNUITY_RATIO'].corr(train['TARGET']))
print(train['AMT_CREDIT'].corr(train['TARGET']))-0.024740288335190132
-0.02255843084934759
del train['AMT_CREDIT']
del test['AMT_CREDIT']AMT_CREDIT과 TARGER의 상관계수가 더 낮으므로 제거해 준다.
input_var = ['FLAG_OWN_REALTY', 'CNT_CHILDREN',
'AMT_INCOME_TOTAL', 'AMT_ANNUITY', 'REGION_POPULATION_RELATIVE',
'DAYS_BIRTH', 'DAYS_EMPLOYED', 'DAYS_ID_PUBLISH', 'OWN_CAR_AGE',
'HOUR_APPR_PROCESS_START', 'DAYS_LAST_PHONE_CHANGE',
'AMT_REQ_CREDIT_BUREAU_YEAR', 'AMT_CREDIT_TO_ANNUITY_RATIO',
'AMT_CREDIT_SUM', 'DAYS_CREDIT', 'CNT_CREDIT_PROLONG', 'count']제거한 변수들을 제외한 나머지 변수들을 input_var에 다시 저장해 준다.
-xgboost 모델링
: shap value를 활용하기 위해서는 모델이 랜덤 포레스트 형태의 tree형 모델이어야 한다. 이 중 xgboost가 속도가 빠르면서 높은 성능을 유지하므로 선택.
from xgboost import XGBClassifiermodel = XGBClassifier(n_estimators=100, learning_rate=0.1)
model.fit(train[input_var],train['TARGET'])
(3) shap value
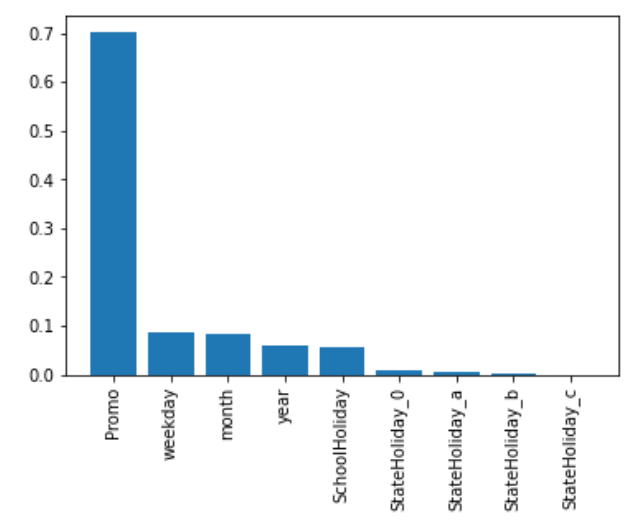
import shapshap_values = shap.TreeExplainer(model).shap_values(train[input_var])shap.summary_plot(shap_values, train[input_var], plot_type='bar')
타겟값에 가장 큰 영향을 미치는 상위 5가지 변수 목록
- AMT_CREDIT_TO_ANNUITY_RATIO
- DAYS_EMPLOYED
- DAYS_CREDIT
- DAYS_BIRTH
- DAYS_LAST_PHONE_CHANGE
(4) 5개의 예측변수와 타겟변수(대출금 상환 여부) 와의 관계
-1. AMT_CREDIT_TO_ANNUITY_RATIO: 대출 상환 기간
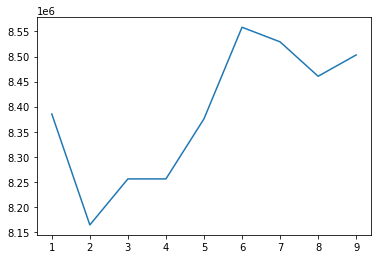
shap.dependence_plot('AMT_CREDIT_TO_ANNUITY_RATIO', shap_values, train[input_var])
해당 그래프는 세로축의 값이 낮을 수록 대출 상환을 잘 한다고 해석(TARGET이 0일 확률이 높음)할 수 있다. 기간이 12-20개월일 때 상환을 잘 하지 못하며, 12개월 이하, 20개월 이상일 때는 비교적 상환을 잘 하는 것으로 보인다.
- 2. DAYS_EMPLOYED: 언제 취업했는지
shap.dependence_plot('DAYS_EMPLOYED', shap_values, train[input_var])
대출일 기준으로 9000일 보다 전에 취업했을 때 대출 상환 능력이 급 상승하는 것을 볼 수 있다.
- 3. DAYS_CREDIT: 해당 대출이 home credit으로부터 받은 대출보다 며칠 이전에 일어났는지
shap.dependence_plot('DAYS_CREDIT', shap_values, train[input_var])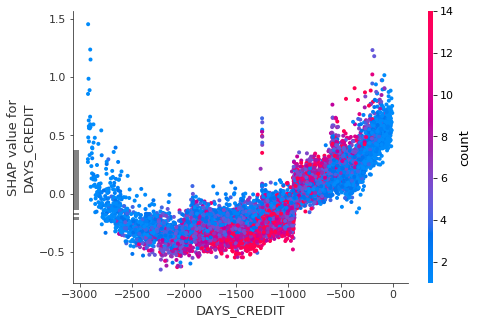
-3000일 부터 -2000일까지 대출 상환 능력이 상승하다가 그 이후부터 하락하는 것을 볼 수 있다. 즉 너무 오래 전에 대출을 받았거나, 최근에 대출을 받았을 때 대출 상환 능력이 떨어진다고 할 수 있다.
- 4. DAYS_BIRTH: 나이
shap.dependence_plot('DAYS_BIRTH', shap_values, train[input_var])
태어난지 오래 되었을 수록(나이가 많을 수록) 대출상환을 잘하는 경향을 보인다.
- 5. DAYS_LAST_PHONE_CHANGE: 마지막 핸드폰을 바꾼 시기
shap.dependence_plot('DAYS_LAST_PHONE_CHANGE', shap_values, train[input_var])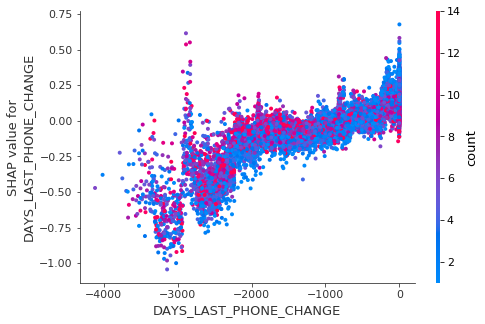
핸드폰을 오래 전에 바꾸었을 수록 대출 상환을 잘하는 경향이 보인다.
3. 결론
- 대출 상환 기간이 상환여부에 가장 큰 영향을 준다. 해당 영향은 비선형적 관계이다. (영향이 크다고 해서 인과관계가 있다고 단정짓기는 어렵다. )
- 주택 보유 여부와 자식의 수는 대출 상환능력에 영향을 거의 미치지 않는다.
- 최근에 취업했을 수록, 최근에 대출을 받았을 수록, 최근에 핸드폰을 바꿨을 수록, 나이가 어릴수록 대출금 상황 가능성이 낮다.
train['DAYS_EMPLOYED'].quantile(0.75)-748.0
위와 같은 방법으로 상위 25%의 값을 구할 수 있다. 이를 이용하여 4개의 변수의 상위 25% 이상 그룹과 하위 25%미만 그룹을 나누어 시각화 결과를 확인 해 본다.
- 상위 25%
group1 = train.loc[ (train['DAYS_EMPLOYED'].quantile(0.75)< train['DAYS_EMPLOYED']) &
(train['DAYS_CREDIT'].quantile(0.75)< train['DAYS_CREDIT']) &
(train['DAYS_LAST_PHONE_CHANGE'].quantile(0.75)< train['DAYS_LAST_PHONE_CHANGE']) &
(train['DAYS_BIRTH'].quantile(0.75)< train['DAYS_BIRTH']) ]- 하위 25 %
group2 = train.loc[ (train['DAYS_EMPLOYED'].quantile(0.25)> train['DAYS_EMPLOYED']) &
(train['DAYS_CREDIT'].quantile(0.25)> train['DAYS_CREDIT']) &
(train['DAYS_LAST_PHONE_CHANGE'].quantile(0.25)> train['DAYS_LAST_PHONE_CHANGE']) &
(train['DAYS_BIRTH'].quantile(0.25)> train['DAYS_BIRTH']) ]group1['group'] = 1
group2['group'] = 0group1은 group변수에 1을, group2는 group 변수에 0을 넣어 준다.
full = pd.concat([group1,group2],axis=0)group1과 group2를 합쳐준다.
import seaborn as snssns.barplot('group','TARGET',data=full)
group2 (group=0, 하위 25%) 의 Target값이 낮은 것을 볼 수 있다(0이 많다=정상 상환). 각 변수들의 값이 작을 수록 대출 상환 가능성이 높다는 결론과 같음을 알 수 있다.
'데이터 분석 이론 > 머신러닝' 카테고리의 다른 글
| [rossmann data]상점 매출 예측/ kaggle 축소데이터 (0) | 2021.09.09 |
|---|---|
| [FIFA DATA] 2019/2020 시즌 Manchester United 에 어떤 선수를 영입해야 하는가?, EDA 과정 (0) | 2021.09.06 |
| [머신러닝] 변수중요도, shap value (0) | 2021.08.27 |
| [Bank Marketing데이터 분석] 2. python 부스팅 Boosting, XGBoost 사용 (0) | 2021.08.23 |
| [Bank Marketing데이터 분석] 1. python 배깅 , 랜덤포레스트 bagging, randomforest (0) | 2021.08.23 |