본 포스트는 패스트캠퍼스 파이썬 기초부터 시작하는 딥러닝 영상인식 바이블 강의를 정리한 글입니다.
올해 상반기가 지나가기 전 딥러닝 공부를 깊게 해보고 싶었다. CNN, RNN, LSTM 등의 이론은 학부생활을 하면서 꽤나 익혔는데, 딥러닝 프레임워크를 사용하여 모델링하는 것은 해보지 않았기에, 프레임워크 중 한 가지 정도는 능숙하게 사용하는 것을 목표로 삼게 되었다. 강의를 따라 keras를 사용할 예정인데,
keras 문서 를 들어가 사용법을 볼 수 있고, 기본적인 모델링은 문서를 통해 배울 수 있을 것 같다.
1. 필요 라이브러리 import
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
import math
print(tf.__version__) # tensorflow 버전 확인tensorflow, keras를 import 해준다. 필자는 google colab 에서 실습을 진행하였고, 글을 쓰는 시점을 기준으로 tf 버전 2.8.0 을 사용한다. 이 밖에 필요한 numpy, matplotlib, math를 import 해 준다.
2. batch size, epochs, num_classes 정의
# Define Constants
batch_size = 128
epochs = 100
num_classes = 10batch_size: 데이터를 몇개씩 묶어서 학습할 것인가? -> 128개씩 묶어서 학습하겠다
ephocs: 학습을 반복하는 횟수 -> 100번 학습하겠다
num_classes: 클래스의 개수 -> MNIST는 0~9까지 10개이므로 10
- 60000장의 데이터를 한번에 학습하지 않고 batch size를 설정하는 이유
배치를 나눠서 학습하게되면 모든 데이터가 스트레이트로 쭉 학습되는 것이 아니라, batch size만큼 학습되면서 예측 값이 맞거나 틀린 경우가 각 배치마다 업데이트 되기 때문에 중간중간 가중치가 조절될 수 있으므로 더 좋은 성능을 기대해볼 수 있다.
(실제로 실험해보았더니 batch size를 60000장으로 했을 때 정확도가 0.02정도 낮게 나왔다. (MNIST 데이터 기준) 그리고 batch size가 작아질 수록 학습 속도가 느려진다. 아직 배치사이즈를 조정할 레벨은 아니지만, 배치사이즈에 따라 성능이 달라지는 것을 직접 확인하니 적절한 배치사이즈를 설정해주는 것도 중요한 부분인 것 같아보인다. )
3. MNIST 데이터셋 불러오기
# Download MNIST dataset
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()워낙 유명한 MNIST 데이터셋은 keras에서 제공해주므로 따로 다운받을 필요 없이 위와 같은 코드를 작성하여 사용할 수 있다.
len(train_images), len(test_images)(60000, 10000)
train은 60000장, test는 10000장임을 알 수 있다.
4. 딥러닝 모델 학습
(1) normailze (0.0 ~ 1.0 사이의 값이 되도록)
# Normalize the input image so that each pixel value is between 0 to 1
train_images = train_images / 255.0
test_images = test_images / 255.0데이터를 float형으로 만들면서 0.0~1.0 사이로 정규화해준다.
(2) 딥러닝 모델 정의
# Define the model architecture
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(num_classes, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])모델은 keras.Sequential에 층을 하나하나 추가해주는 방식이다. 직관적으로 모델링을 할 수 있다는 장점이 있다. flatten으로 한 장당 2차원 배열 28x28인 이미지를 1차원으로 만들어 준다. 그다음 Dense layer를 사용하고, activation 함수는 relu를 사용한다. 마지막 층에는 클래스의 개수와 softmax 함수를 사용함으로써 예측 결과를 클래스 별 확률로 나오게끔 만들어준다.
model.complie로 optimizer와 loss함수, metrics (평가지표)를 설정해 준다.
이제 모델 학습할 모든 준비가 되었다.
(3) 딥러닝 모델 학습
history = model.fit(train_images, train_labels, epochs=epochs, batch_size=batch_size)train 데이터셋과 앞서 지정했던 ephocs, batch_size를 설정해 준다.
5. 딥러닝 모델 평가
(1) loss, accuracy 확인
test_loss, test_acc = model.evaluate(test_images, test_labels)
print("Test Loss: ", test_loss)
print("Test Accuracy: ", test_acc)Test Loss: 0.12909765541553497
Test Accuracy: 0.98089998960495
아주 기본적인 딥러닝 모델을 사용하였음에도 불구하고 0.98이라는 높은 정확도가 나왔다. 모든 학습 결과가 이랬으면 좋겠다.
(2) 필요 함수 정의
# 1. 원하는 개수만큼 이미지를 보여주는 함수
def show_sample(images, labels, sample_count=25):
# Create a square with can fit {sample_count} images
grid_count = math.ceil(math.ceil(math.sqrt(sample_count)))
grid_count = min(grid_count, len(images), len(labels))
plt.figure(figsize=(2*grid_count, 2*grid_count))
for i in range(sample_count):
plt.subplot(grid_count, grid_count, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(images[i], cmap=plt.cm.gray)
plt.xlabel(labels[i])
plt.show()
###################################################################
# 2. 특정 숫자의 이미지를 보여주는 함수
# Helper function to display specific digit images
def show_sample_digit(images, labels, digit, sample_count=25):
# Create a square with can fit {sample_count} images
grid_count = math.ceil(math.ceil(math.sqrt(sample_count)))
grid_count = min(grid_count, len(images), len(labels))
plt.figure(figsize=(2*grid_count, 2*grid_count))
i = 0
digit_count = 0
while digit_count < sample_count:
i += 1
if digit == labels[i]:
plt.subplot(grid_count, grid_count, digit_count+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(images[i], cmap=plt.cm.gray)
plt.xlabel(labels[i])
digit_count += 1
plt.show()
###################################################################
# 3.이미지 한개를 크게 보여주는 함수
def show_digit_image(image):
# Draw digit image
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
# Major ticks every 20, minor ticks every 5
major_ticks = np.arange(0, 29, 5)
minor_ticks = np.arange(0, 29, 1)
ax.set_xticks(major_ticks)
ax.set_xticks(minor_ticks, minor=True)
ax.set_yticks(major_ticks)
ax.set_yticks(minor_ticks, minor=True)
# And a corresponding grid
ax.grid(which='both')
# Or if you want different settings for the grids:
ax.grid(which='minor', alpha=0.2)
ax.grid(which='major', alpha=0.5)
ax.imshow(image, cmap=plt.cm.binary)
plt.show()28x28 배열의 이미지를 시각화로 확인해볼 수 있도록 해주는 함수이다.
위 함수를 사용하여 잠깐 이미지를 확인해 보자.
- show_sample 함수 사용 (원하는 개수만큼 사진 출력)
show_sample(train_images, ['Label: %s' % label for label in train_labels])
이렇게 원하는 개수 만큼 이미지를 확인해볼 수 있다.
- show_sample_digit 함수 사용 (특정 숫자에 대한 원하는 개수만큼의 사진 출력)
show_sample_digit(train_images, train_labels, 7)
특정 숫자를 원하는 개수만큼 확인해볼 수 있다.
(3) train 데이터셋 학습 시 ephoch에 따른 loss와 accuracy 값 시각화
# Evaluate the model using test dataset. - Show performance
fig, loss_ax = plt.subplots()
fig, acc_ax = plt.subplots()
loss_ax.plot(history.history['loss'], 'ro')
loss_ax.set_xlabel('ephoc')
loss_ax.set_ylabel('loss')
acc_ax.plot(history.history['accuracy'], 'bo')
acc_ax.set_xlabel('ephoc')
acc_ax.set_ylabel('accuracy')
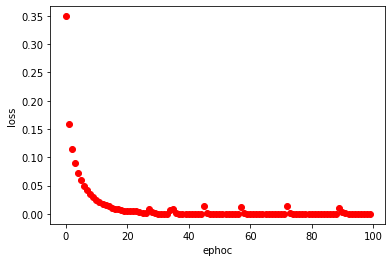
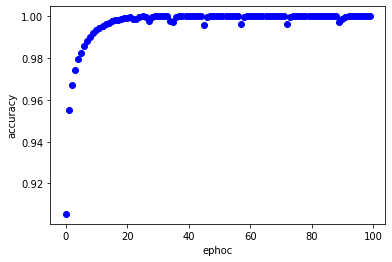
(4) test data의 예측 값과 정답 값 비교해보기
- 실제값: 그림
- 예측값: x label
# Predict the labels of digit images in our test datasets.
predictions = model.predict(test_images)
# Then plot the first 25 test images and their predicted labels.
show_sample(test_images, ['predicted: %s' % np.argmax(result) for result in predictions])

(5) show_digit_image 함수 사용
- 특정 인덱스의 사진과 그때의 예측값을 비교해 봄
Digit = 2005 #@param {type:'slider', min:1, max:10000, step:1}
selected_digit = Digit - 1
result = predictions[selected_digit]
result_number = np.argmax(result)
print('Number is %2d' % result_number)
show_digit_image(test_images[selected_digit])
#@param을 사용하면 위와 같이 슬라이더가 생긴다. 랜덤으로 슬라이드를 해서 인덱스 값을 지정해 주면,
Number is 7

이와 같이 Number is 7 은 예측 값, 이미지는 test 이미지 (정답 값)으로 두개를 비교 확인해볼 수 있다.
이번 포스트에서 사용한 MNIST데이터셋은 아주 간단한 딥러닝 모델인데도 성능이 좋았다.
다음 포스팅에서는 이미지 모델학습에 최적화 되어있는 CNN 모델링을 함으로써 MNIST의 성능을 더욱 높여보는 공부를 해 볼 것이다.
'데이터 분석 이론 > 딥러닝' 카테고리의 다른 글
| [fashion MNIST 프로젝트] 2. fashion MNIST 전처리, 시각화 (0) | 2021.06.09 |
|---|---|
| [fashion MNIST 프로젝트] 1. multi-label 분류, fashion MNIST 데이터 알아보기 (0) | 2021.06.09 |
| [celeba 프로젝트] 3. 모델링, 멀티 아웃풋 모델링 (0) | 2021.06.09 |
| [celeba 프로젝트] 2. celeba 데이터셋 전처리, 시각화 (0) | 2021.06.07 |
| [celeba 프로젝트] 1. celeba 데이터 살펴보기 (0) | 2021.06.07 |